
In this post, we are going to compare the replication functionality in the two most popular database systems on the planet (according to db-engines) - Oracle and MySQL. We’ll specifically look at Oracle 12c logical replication, and MySQL 5.7. Both technologies offer reliable standby systems to offload production workloads and help in case of disaster. We will take a look at their different architectures, analyze pros and cons and go through the steps on how to setup replication with Oracle and MySQL.
Oracle Data Guard Architecture – How it works
Oracle Data Guard assures high availability, data protection, and disaster recovery of your data. It's probably an Oracle DBA’s first choice for replicating data. The technology was introduced in 1990 (version 7.0) with an essential apply of archive logs on standby databases. Data Guard evolved over the years and now provides a comprehensive set of services that create, maintain, manage, and monitor standby databases.
Data Guard maintains standby databases as copies of the production database. If the primary database stops responding, Data Guard can switch any standby to the production role, thus downtime. Data Guard can be used for backup, restoration, and cluster techniques to provide a high level of data protection and data availability.
Data Guard is a Ship Redo / Apply Redo technology, "redo" is the information needed to recover transactions. A production database referred to as a primary database broadcasts redo to one or more replicas referred to as standby databases. When an insert or update is made to a table, this change is captured by the log writer into an archive log, and replicated to the standby system. Standby databases are in a continuous phase of recovery, verifying and applying redo to maintain synchronization with the primary database. A standby database will also automatically re-synchronize if it becomes temporarily disconnected to the primary due to power outages, network problems, etc.
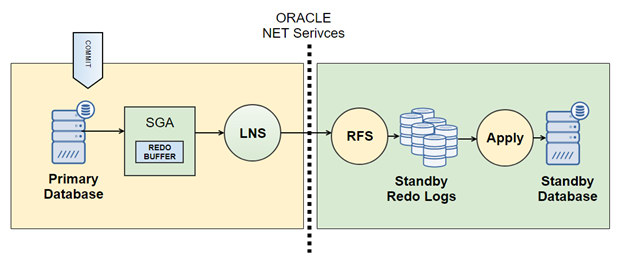
Oracle Data Guard Net Services
Data Guard Redo Transport Services regulate the transmission of redo from the primary database to the standby database. LGWR (log writer) process submits the redo data to one or more network server (LNS1, LSN2, LSN3, ...LSNn) processes. LNS is reading from the redo buffer in the SGA (Shared Global Area) and passes redo to Oracle Net Services to transmit to the standby database. You can choose the LGWR attributes: synchronous (LogXptMode = 'SYNC') or asynchronous mode (LogXptMode = 'ASYNC'). With such architecture it is possible to deliver the redo data to several standby databases or use it with Oracle RAC (Real Application Cluster). The Remote File Server (RFS) process receives the redo from LNS and writes it to a regular file called a standby redo log (SRL) file.
There are two major types of Oracle Data Guard. Physical with redo apply and Logical standby databases with SQL apply.
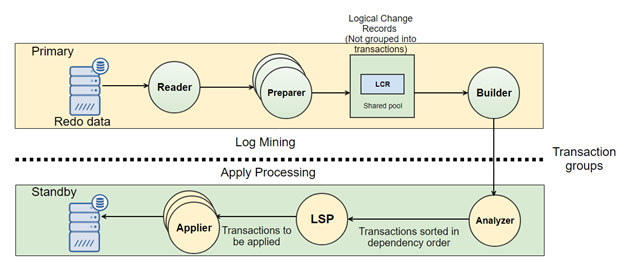
Oracle Dataguard Logical Replication architecture
SQL apply requires more processing than redo applies, the process first read the SRL and "mine" the redo by converting it to logical change records, and then builds SQL transactions before applying the SQL to the standby database. There are more moving parts so it requires more CPU, memory and I/O then redo apply.
The main benefit of "SQL apply" is that the database is open to read-write, while the apply process is active.
You can even create views and local indexes. This makes it ideal for reporting tools. The standby database does not have to be a one to one copy of your primary database, and therefore may not be the best candidate for DR purposes.
The key features of this solution are:
- A standby database that is opened for read-write while SQL apply is active
- Possible modification lock of data that is being maintained by the SQL apply
- Able to execute rolling database upgrades
There are drawbacks. Oracle uses a primary-key or unique-constraint/index supplemental logging to logically recognize a modified row in the logical standby database. When database-wide primary-key and unique-constraint/index supplemental logging is enabled, each UPDATE statement also writes the column values necessary in the redo log to uniquely identify the modified row in the logical standby database. Oracle Data Guard supports chained replication, which here is called “cascade” however it’s not typical due to the complexity of the setup.
Oracle recommends that you add a primary key or a non-null unique index to tables in the primary database, whenever possible, to ensure that SQL Apply can efficiently apply redo data updates to the logical standby database. This means it doesn’t work on any setup, you may need to modify your application.
Oracle Golden Gate Architecture – How it works
With Data Guard, as blocks are changed in the database, records are added to the redo log. Then based on the replication mode that you are running, these log records will either be immediately copied to the standby or mined for SQL commands and applied. Golden Gate works in a different way.
Golden Gate only replicates changes after the transaction is committed, so if you have a long running transaction, it can take a while to replicate. The Golden Gate “extract process” keeps transactional changes in memory.
Another big difference is that Oracle Golden Gate enables the exchange and manipulation of data at the transaction level among multiple, heterogeneous platforms. You are not only limited to Oracle database. It gives you the flexibility to extract and replicate selected data records, transactional changes, and changes to DDL (data definition language) across a variety of topologies.
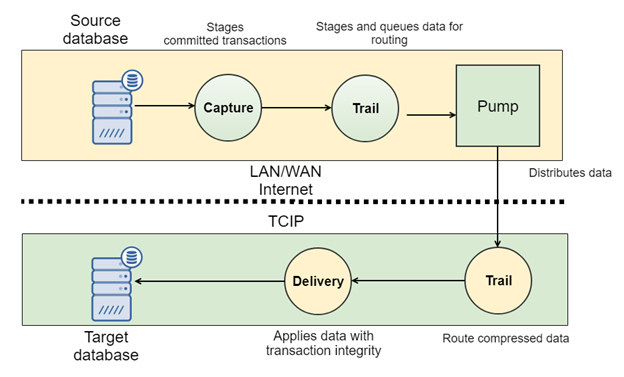
Oracle Golden Gate architecture
The typical Golden Gate flow shows new and changed database data being captured from the source database. The captured data is written to a file called the source trail. The trail is then read by a data pump, sent across the network, and written to a remote trail file by the Collector process. The delivery function reads the remote trail and updates the target database. Each of the components is managed by the Manager process.
MySQL Logical replication – How it works
Replication in MySQL has been around for a long time and has been evolving over the years. There are different ways to enable MySQL replication, including Group Replication, Galera Clusters, asynchronous "Master to Slave". To compare Oracle vs. MySQL architecture, we will focus on replication formats as it is the base for all the various replication types.
First of all, the different replication formats correspond to the binary logging format specified in my.cnf configuration file. Regardless of the format, logs are always stored in a binary way, not viewable with a regular editor. There are three format types: row-based, statement based and mixed. Mixed is the combination of first two. We will take a look at statement and row based.
Statement based – in this case these are the written queries. Not all statements that modify data (such as INSERT DELETE, UPDATE, and REPLACE statements) can be replicated using statement-based replication. LOAD_FILE(), UUID(), UUID_SHORT(), USER(), FOUND_ROWS() etc will be not replicated.
Row-based – in this case, these are changes to records. All changes can be replicated. This is the safest form of replication. Since 5.7.7, it’s the default option.
Now let's take a look what is happening under the hood when replication is enabled.
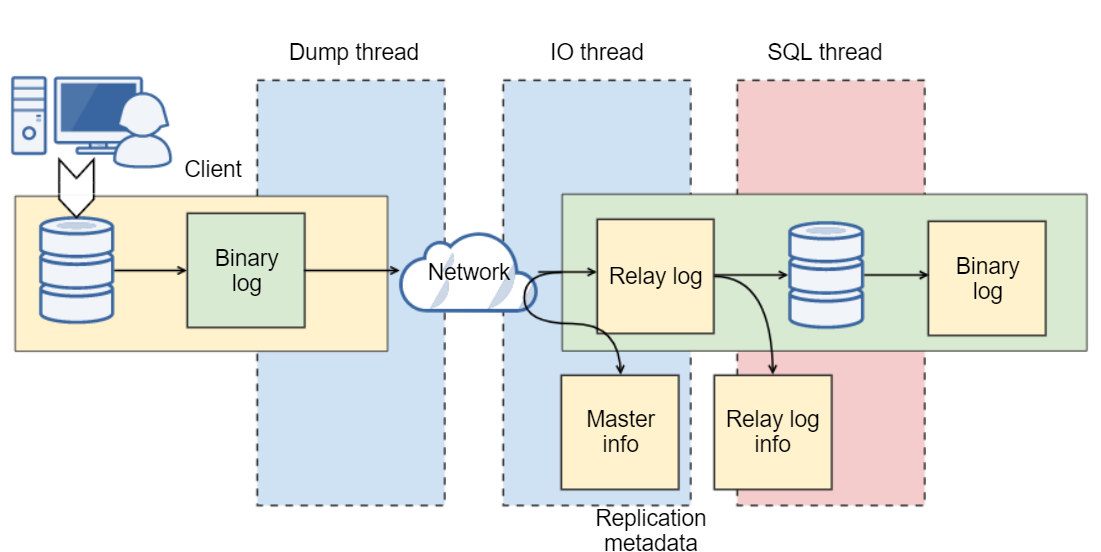
MySQL replication architecture
First of all, the master database writes changes to a file called binary log or binlog. Writing to binary log is usually a lightweight activity because writes are buffered and sequential. The binary log file stores data that a replication slave will be processing later, the master activity doesn’t depend on them. When the replication starts, mysql will trigger three threads. One on the master, two on the slave. The master has a thread, called the dump thread, that reads the master's binary log and delivers it to the slave.
On the slave, a process called IO thread connects to the master, reads binary log events from the master as they come in and copies them over to a local log file called relay log. The second slave process – SQL thread – reads events from a relay log stored locally on the replication slave and then utilizes them.
MySQL supports chained replication, which is very easy to setup. Slaves which are also masters must be running with --log-bin and --log-slave-update parameters.
To check the status of the replication and get information about threads, you run on the slave:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| MariaDB [(none)]> show slave status\G*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: master Master_User: rpl_user Master_Port: 3306 Connect_Retry: 10 Master_Log_File: binlog.000005 Read_Master_Log_Pos: 339 Relay_Log_File: relay-bin.000002 Relay_Log_Pos: 635 Relay_Master_Log_File: binlog.000005 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 339 Relay_Log_Space: 938 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 Master_SSL_Crl: Master_SSL_Crlpath: Using_Gtid: Current_Pos Gtid_IO_Pos: 0-1-8 Replicate_Do_Domain_Ids: Replicate_Ignore_Domain_Ids: Parallel_Mode: conservative SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it1 row in set (0.00 sec) |
Setting up Data Guard Logical replication in Oracle
Create a Physical Standby Database
To create a logical standby database, you first create a physical standby database and then transition it to a logical standby database.Stop Redo Apply on the Physical Standby Database
Stopping Redo Apply is necessary to avoid applying changes.1SQL>ALTERDATABASERECOVER MANAGED STANDBYDATABASECANCEL;Prepare the Primary Database to Support a Logical Standby Database
Change the VALID_FOR attribute in the original LOG_ARCHIVE_DEST_1 and add LOG_ARCHIVE_DEST_3 for logical database.123456789LOG_ARCHIVE_DEST_1='LOCATION=/arch1/severalnines/VALID_FOR=(ONLINE_LOGFILES,ALL_ROLES)DB_UNIQUE_NAME=severalnines'LOG_ARCHIVE_DEST_3='LOCATION=/arch2/severalnines/VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE)DB_UNIQUE_NAME=severalnines'LOG_ARCHIVE_DEST_STATE_3=ENABLEBuild a Dictionary in the Redo Data
1SQL>EXECUTEDBMS_LOGSTDBY.BUILD;Convert to a Logical Standby Database
To continue applying redo data to the physical standby database until it is ready to convert to a logical standby database, issue the following SQL statement:1SQL>ALTERDATABASERECOVERTOLOGICAL STANDBY db_name;Adjust Initialization Parameters for the Logical Standby Database
123456789101112131415LOG_ARCHIVE_DEST_1='LOCATION=/arch1/severalnines_remote/VALID_FOR=(ONLINE_LOGFILES,ALL_ROLES)DB_UNIQUE_NAME=severalnines_remote'LOG_ARCHIVE_DEST_2='SERVICE=severalnines ASYNCVALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE)DB_UNIQUE_NAME=severalnines'LOG_ARCHIVE_DEST_3='LOCATION=/arch2/severalnines_remote/VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE)DB_UNIQUE_NAME=severalnines_remote'LOG_ARCHIVE_DEST_STATE_1=ENABLELOG_ARCHIVE_DEST_STATE_2=ENABLELOG_ARCHIVE_DEST_STATE_3=ENABLEOpen the Logical Standby Database
1SQL>ALTERDATABASEOPENRESETLOGS;Verify the Logical Standby Database Is Performing Properly
v$data_guard_stats view
123456789SQL> COLNAMEFORMAT A20SQL> COL VALUE FORMAT A12SQL> COL UNIT FORMAT A30SQL>SELECTNAME, VALUE, UNITFROMV$Data_Guard_STATS;NAMEVALUE UNIT-------------------- ------------ ------------------------------apply finishtime+00 00:00:00day(2)tosecond(1) intervalapply lag +00 00:00:00day(2)tosecond(0) intervaltransport lag +00 00:00:00day(2)tosecond(0) intervalv$logstdby_process view
123456789101112131415SQL>COLUMNSERIAL# FORMAT 9999SQL>COLUMNSID FORMAT 9999SQL>SELECTSID, SERIAL#, SPID, TYPE, HIGH_SCNFROMV$LOGSTDBY_PROCESS;SID SERIAL# SPID TYPE HIGH_SCN----- ------- ----------- ---------------- ----------48 6 11074 COORDINATOR 717824289956 56 10858 READER 717824349746 1 10860 BUILDER 717824290145 1 10862 PREPARER 717824329537 1 10864 ANALYZER 717824290036 1 10866 APPLIER 717823946735 3 10868 APPLIER 717823946334 7 10870 APPLIER 717823946133 1 10872 APPLIER 71782394729rowsselected.
These are the necessary steps to create Oracle Data Guard logical replication. Actions will be slightly different if you perform this operation with non default compatibility set or databases running in Oracle RAC environment.
Setting up MySQL replication
- Configure Master database. Set unique server_id, specify different replication logs –log-basename (MariaDB) , activate binary log. Modify my.cnf file with below information.123
log-binserver_id=1log-basename=master1Login to master database and grant replication user to access master data.1GRANTREPLICATION SLAVEON*.*TOreplication_user - Start both servers with GTIDs enabled.12
gtid_mode=ONenforce-gtid-consistency=true - Configure the slave to use GTID-based auto-positioning.123456
mysql> CHANGE MASTERTO> MASTER_HOST = host,> MASTER_PORT = port,> MASTER_USER = replication_user,> MASTER_PASSWORD =password,> MASTER_AUTO_POSITION = 1; - If you want to add slave to master with data, then you need to take backup and restore it on slave server.1
mysqldump --all-databases --single-transaction --triggers --routines --host=127.0.0.1 --user=root --password=rootpassword > dump_replication.sqlLogin to slave database and execute:123slave> tee dump_replication_insert.logslave> source dump_replication.sqlslave> CHANGE MASTERTOMASTER_HOST="host", MASTER_USER=" replication_user ", MASTER_PASSWORD="password ", MASTER_PORT=port, MASTER_AUTO_POSITION = 1;
No comments:
Post a Comment